▣ 앙상블(Ensemble) 기법과 배깅(Bagging), 부스팅(Boosting), 스태킹(Stacking)
앙상블은 여러 개의 분류기를 생성하고 그 예측을 결합함으로써 보다 정확한 최종 예측을 도출하는 기법
앙상블 학습의 유형은 보팅(Voting), 배깅(Bagging), 부스팅(Boosting), 스태킹(Stacking)을 포함한 다양한 앙상블 방식이 있음
■ 보팅(Voting) - Hard vs Soft
| 하드 보팅(Hard Voting) | 다수결 원칙과 유사 예측한 결과값들 중 다수의 분류기가 결정한 예측값을 최종 보팅 결과값으로 선정 |
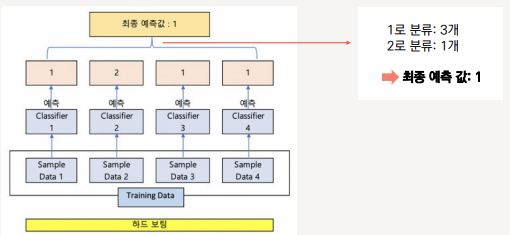 |
| 소프트 보팅(Soft Voting) | 분류기들의 레이블 값 결정 확률을 모두 더해 이를 평균내서 확률이 가장 높은 레이블 값을 최종 보팅 결과값을 선정 |  |
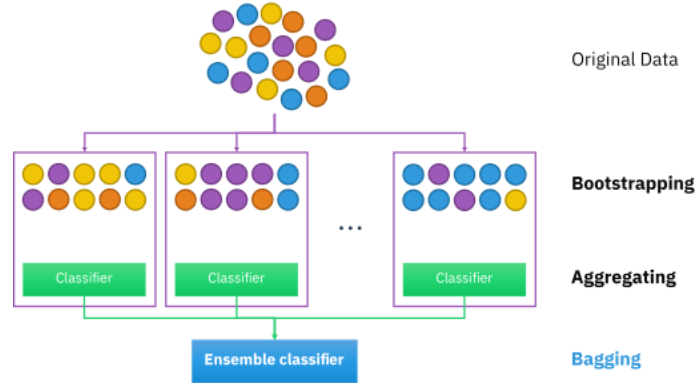
■ 배깅(Bagging)
배깅(Bagging) : Bootstrap aggreagting 부트스트랩을 집계
부트스트랩(bootstrap)은 통계학에서 사용하는 용어로, random sampling을 적용하는 방법
각각의 분류기들이 학습시 상호영향을 주지 않은 상황에서(독립적) 학습이 끝난 다음 결과를 종합하는 기법
배깅(Bagging)은 부트스트랩(bootstrap)을 집계(Aggregating)하여 학습 데이터가 충분하지 않더라도 충분한 학습효과를 주어 높은 bias의 underfitting 문제나, 높은 variance로 인한 overfitting 문제를 해결하는데 도움을 줌
■ 부스팅(Boosting)
순차적으로, 복원추출로 가중치를 줌
부스팅(Boosting)의 경우도 Bagging과 크게 다르지 않으며 거의 동일한 매커니즘을 갖고 있음
이전 분류기의 학습 결과를 토대로 다음 분류기의 학습 데이터의 샘플 가중치를 조정해 학습을 진행하는 방법
일반적으로 오답에 대해 높은 가중치를 부여하므로 정확도가 높게 나타남
하지만 그렇기 때문에 outlier에 취약할 수 있음
XGBoost와 AdaBoost, GradientBoost 등 다양한 모델이 존재

■ 스태킹(Stacking)
크로스 벨리데이션(Cross Validation) 기반으로 서로 상이한 모델들을 조합
스태킹(Stacking)은 개별 모델이 예측한 데이터를 다시 meta data set으로 사용해서 학습한다는 컨셉
Base Learner들이 동일한 데이터 원본 데이터를 가지고 그대로 학습을 진행했기 때문에 overfitting 문제가 발생
Base Learner의 validation set와 test set을 모아 meta train set와 meta test 셋으로 활용하여 학습한 뒤, 최종 모델을 생성

2021년 98번

정답 : 2번
앙상블은 여러 개의 분류기를 생성하고 그 예측을 결합함으로써 보다 정확한 최종 예측을 도출하는 기법
앙상블 학습의 유형은 보팅(Voting), 배깅(Bagging), 부스팅(Boosting), 스태킹(Stacking)을 포함한 다양한 앙상블 방식이 있음
k-평균 알고리즘(K-means clustering algorithm)은 주어진 데이터를 k개의 클러스터로 묶는 알고리즘으로, 각 클러스터와 거리 차이의 분산을 최소화하는 방식으로 동작
순환신경망(Recurrent Neural Network, RNN)은 입력과 출력을 시퀀스(Sequence) 단위로 처리하는 모델
시퀀스란 연관된 연속의 데이터를 의미하며, 시계열 데이터에 적합한 신경망 모델이라 할 수 있음
LSTM은 제프 호크라이터와 유르겐 슈미트후버가 1997년에 소개했고 아직까지 RNN을 개선한 가장 성공적인 모델로 평가 받고 있음. 이 모델은 훈련이 빠르게 수렴되고 데이터의 장기간 의존성을 감지함
LSTM은 장기 의존성을 해결하기 위해서 셀 상태(Cell state)라는 구조를 만들었음. 데이터를 계산하는 위치에 입력(Input), 망각(Forget), 출력(Output) 게이트 3가지가 추가되어 각 상태 값을 메모리 공간 셀에 저장하고, 데이터를 접하는 게이트 부분을 조정하여 불필요한 연산, 오차 등을 줄여 장기 의존성 문제를 일정 부분 해결함
회귀는 여러 개의 독립 변수와 한 개의 종속 변수 간의 상관관계를 모델링 하는 기법
독립변수가 1개이면 단순회귀(Simple Regression), 독립변수가 2개이상 이면 다중회귀(Multiple Regression)로 분류 할 수 있으며 각각을 또 두가지로 분류 할 수 있는데 회귀계수(기울기, x의상수값)가 선형이면 선형회귀, 비선형이면 비선형 회귀모델로 구분을 할 수 있음
'시스템구조' 카테고리의 다른 글
| 네트워크 구조_무선랜 다중화 기술 FHSS, DSSS, OFDM, TDMA (0) | 2021.12.16 |
|---|---|
| 클라우드_오픈스택(openstack), Horizon, Nova, Neutron, Swift, Cinder, Keystone, Glance (0) | 2021.11.23 |
| SDN (Software Defined Networking), NFV, 노스, 사우스 바운드, 오픈플로우, 오버레이 (0) | 2021.11.18 |
| 컨볼루션 신경망_CNN(Convolution Neural Network) (0) | 2021.11.18 |
| 회선교환방식, 패킷교환방식 비교 (0) | 2021.11.18 |