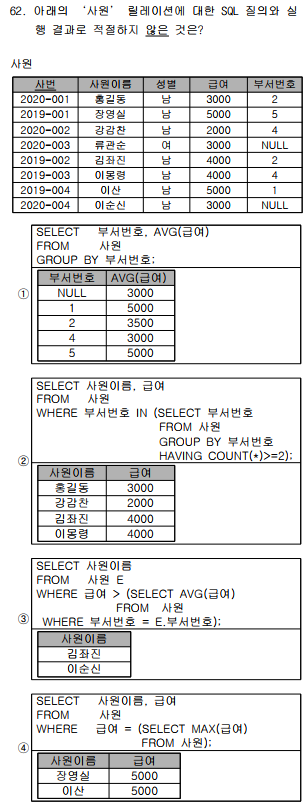
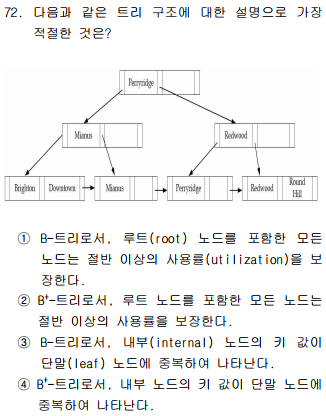
▣ 데이터베이스 시스템 언어_DDL, DML, DCL DDL (Data Definition Language) 데이터베이스를 정의, 수정할 때 사용하는 언어 CREATE, ALTER, RENAME, DROP 등 (암기법 : CARD) DML (Data Manipulation Language) 생성된 데이터베이스의 정보를 검색, 삽입, 삭제, 수정 등의 처리 목적 SELECT, UPDATE, DELETE, INSERT 등 사용자가 무슨 데이터를 어떻게 접근하여 처리해야 하는지를 명세해야 하는 데이터 언어 PL/SQL 등 DCL (Data Control Language) 데이터 베이스를 제어하기 위한 언어 보안, 데이터 무결성, 회복, 병행제어 GRANT, REVOKE, SET 등 TCL COMMIT, ROL..